Introduction
Harmonic progression is one of the cornerstones of tonal music composition and is thereby essential to many musical styles and traditions. Previous studies have shown that musical genres and composers could be discriminated based on chord progressions modeled as chord n-grams. These studies were however conducted on small-scale datasets and using symbolic music transcriptions.
In this work, we apply pattern mining techniques to over 200,000 chord progression sequences out of 1,000,000 extracted from the I Like Music (ILM) commercial music audio collection. The ILM collection spans 37 musical genres and includes pieces released between 1907 and 2013. We developed a single program multiple data parallel computing approach whereby audio feature extraction tasks are split up and run simultaneously on multiple cores. An audio-based chord recognition model (Vamp plugin Chordino) was used to extract the chord progressions from the ILM set. To keep low-weight feature sets, the chord data were stored using a compact binary format. We used the CM-SPADE algorithm, which performs a vertical mining of sequential patterns using co-occurence information, and which is fast and efficient enough to be applied to big data collections like the ILM set. In order to derive key-independent frequent patterns, the transition between chords are modeled by changes of qualities (e.g. major, minor, etc.) and root keys (e.g. fourth, fifth, etc.). The resulting key-independent chord progression patterns vary in length (from 2 to 16) and frequency (from 2 to 19,820) across genres. As illustrated by graphs generated to represent frequent 4-chord progressions, some patterns like circle-of-fifths movements are well represented in most genres but in varying degrees.
These large-scale results offer the opportunity to uncover similarities and discrepancies between sets of musical pieces and therefore to build classifiers for search and recommendation. They also support the empirical testing of music theory. It is however more difficult to derive new hypotheses from such dataset due to its size. This can be addressed by using pattern detection algorithms or suitable visualisation which we present in a companion study.
Dataset
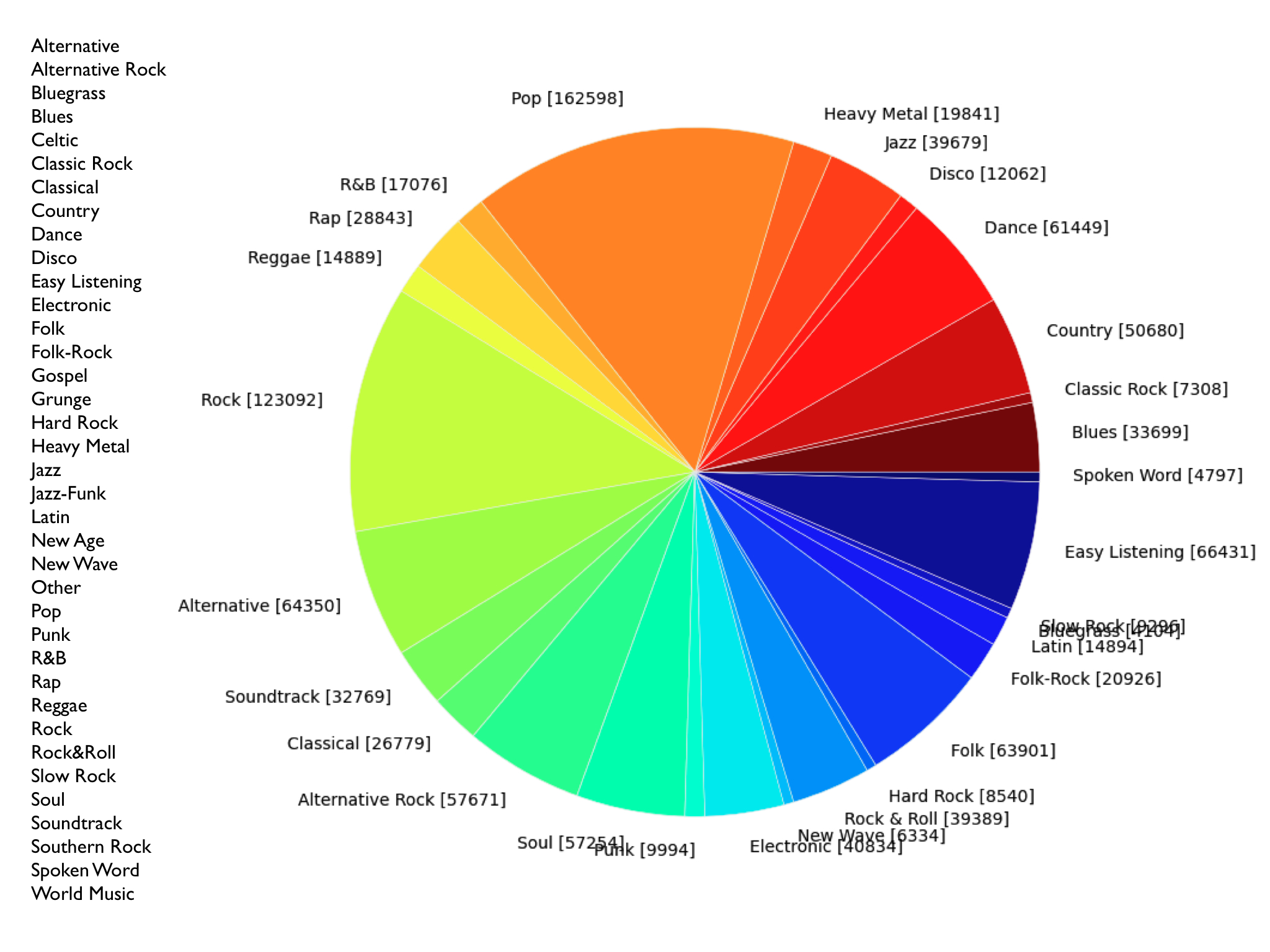
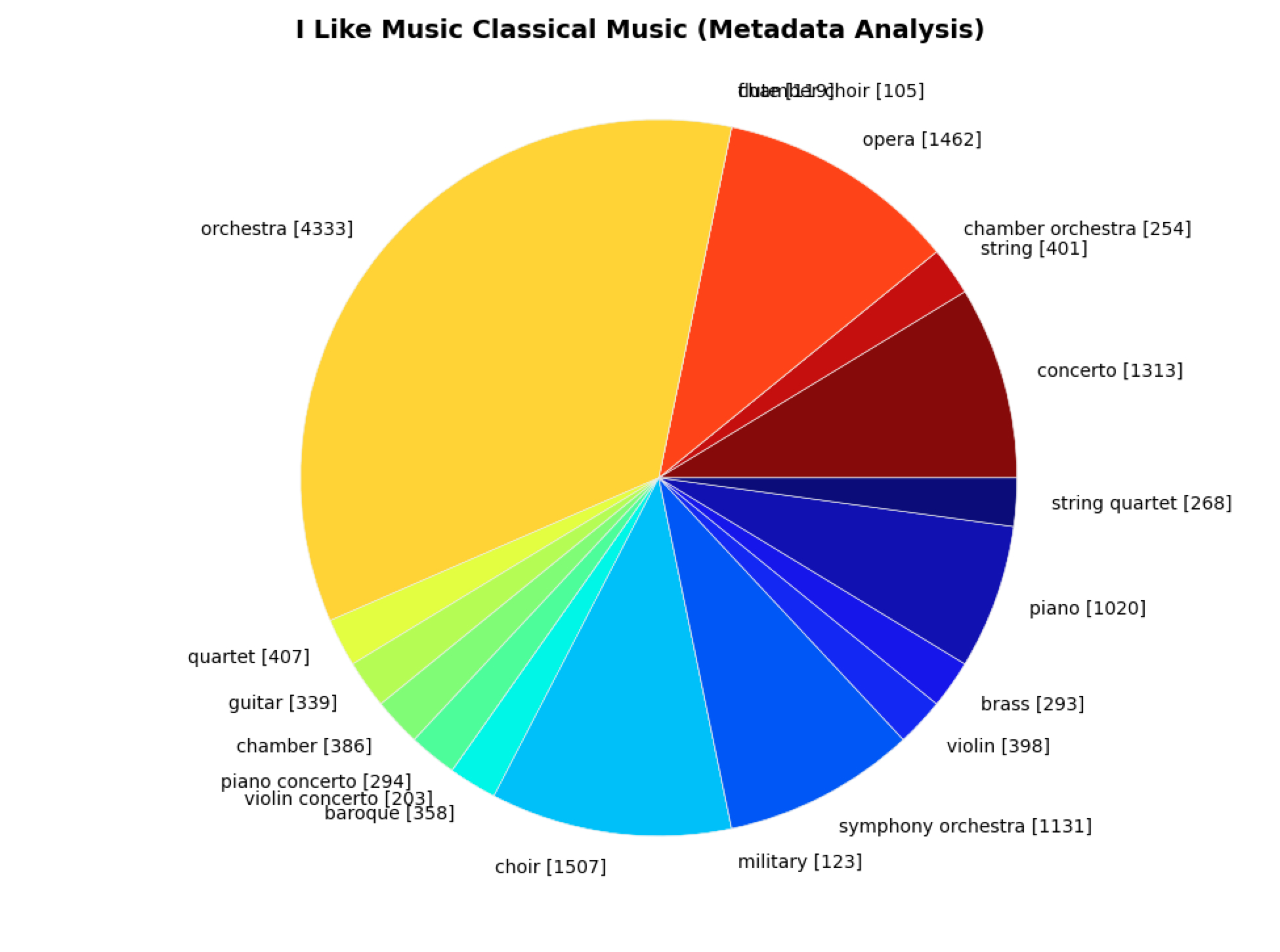
The I Like Music (ILM) commercial library we analysed comprises 1,293,049 musical pieces from 37 different musical genres with release years ranging from 1907 to 2013. The links below show figures of the dataset across genres and release years.
Overview of the I Like Music (ILM) dataset across musical genre. The total number of pieces in each genre is reported in square brackets. ILM's genres are defined according to the ID3 tag standard.
{kind=link}
Number of pieces in the I Like Music (ILM) commercial library as a function of their release year
{kind=link}
{kind=link}
Most frequent chord progression patterns
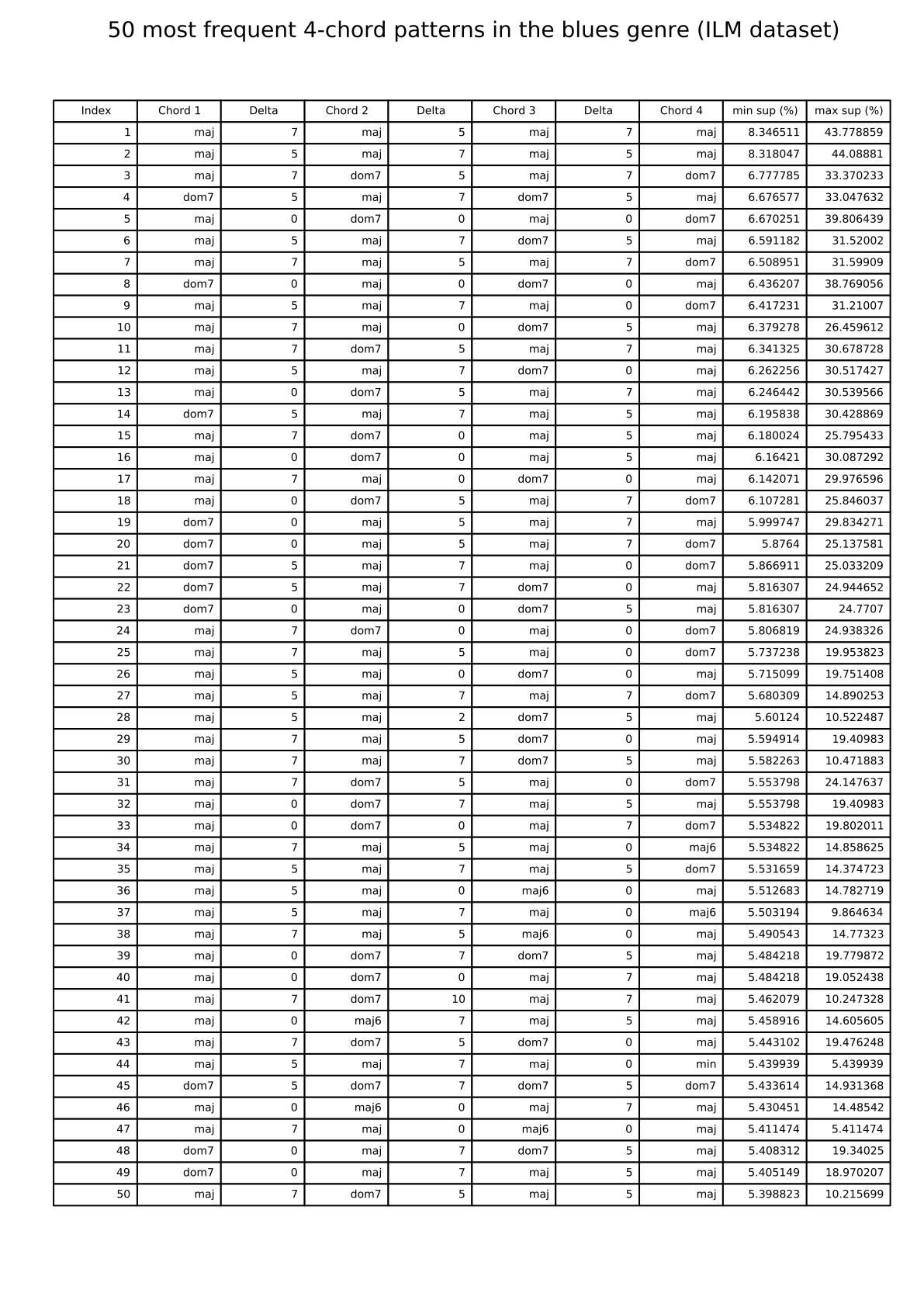
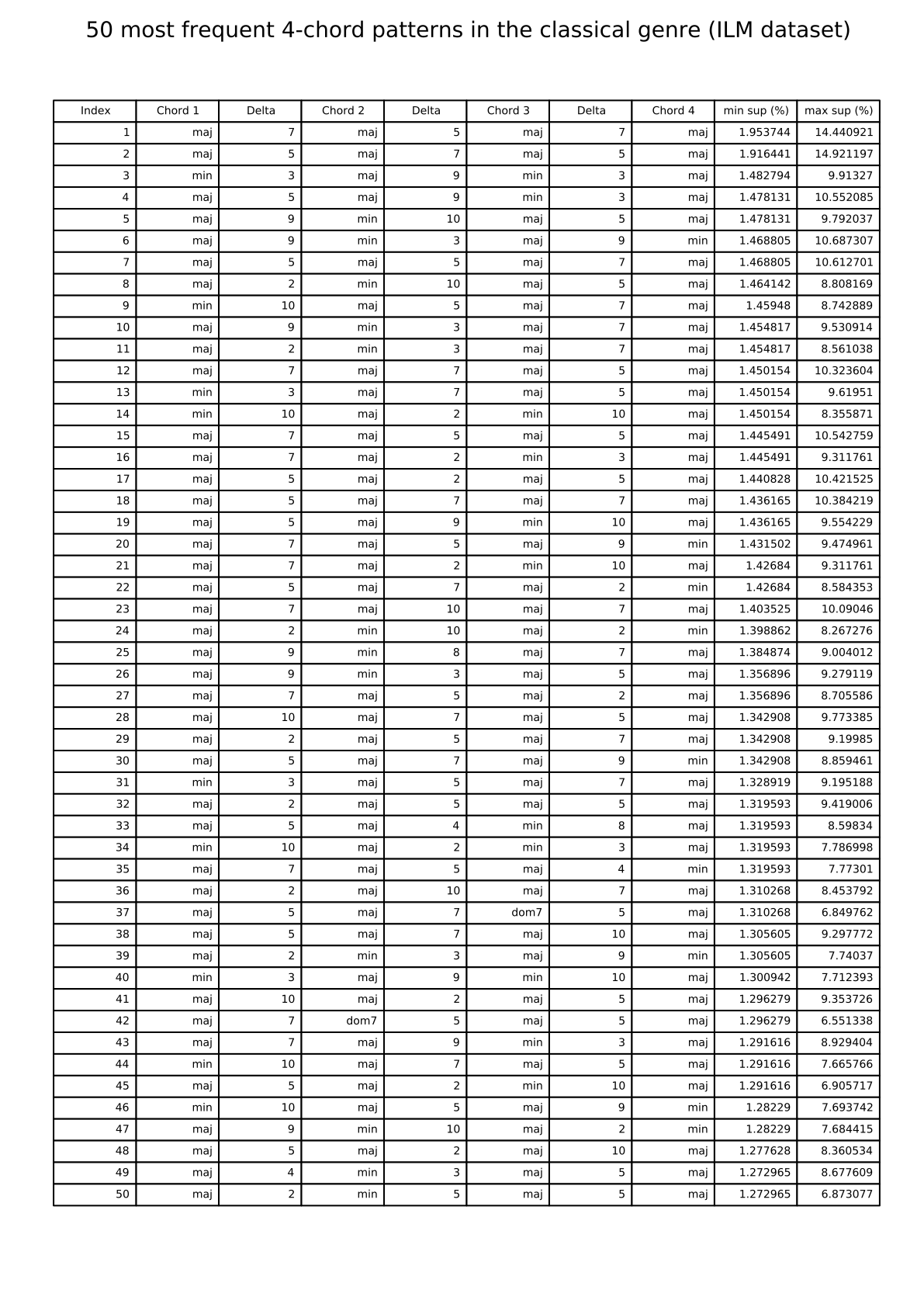
The links below show tables listing the 50 most frequent 4-chord patterns in pieces from the I Like Music commercial music collection, for six different genres.
Blues: 50 most frequent 4-chord patterns
{kind=link}
Classical: 50 most frequent 4-chord patterns
{kind=link}
Folk: 50 most frequent 4-chord patterns (ILM dataset)
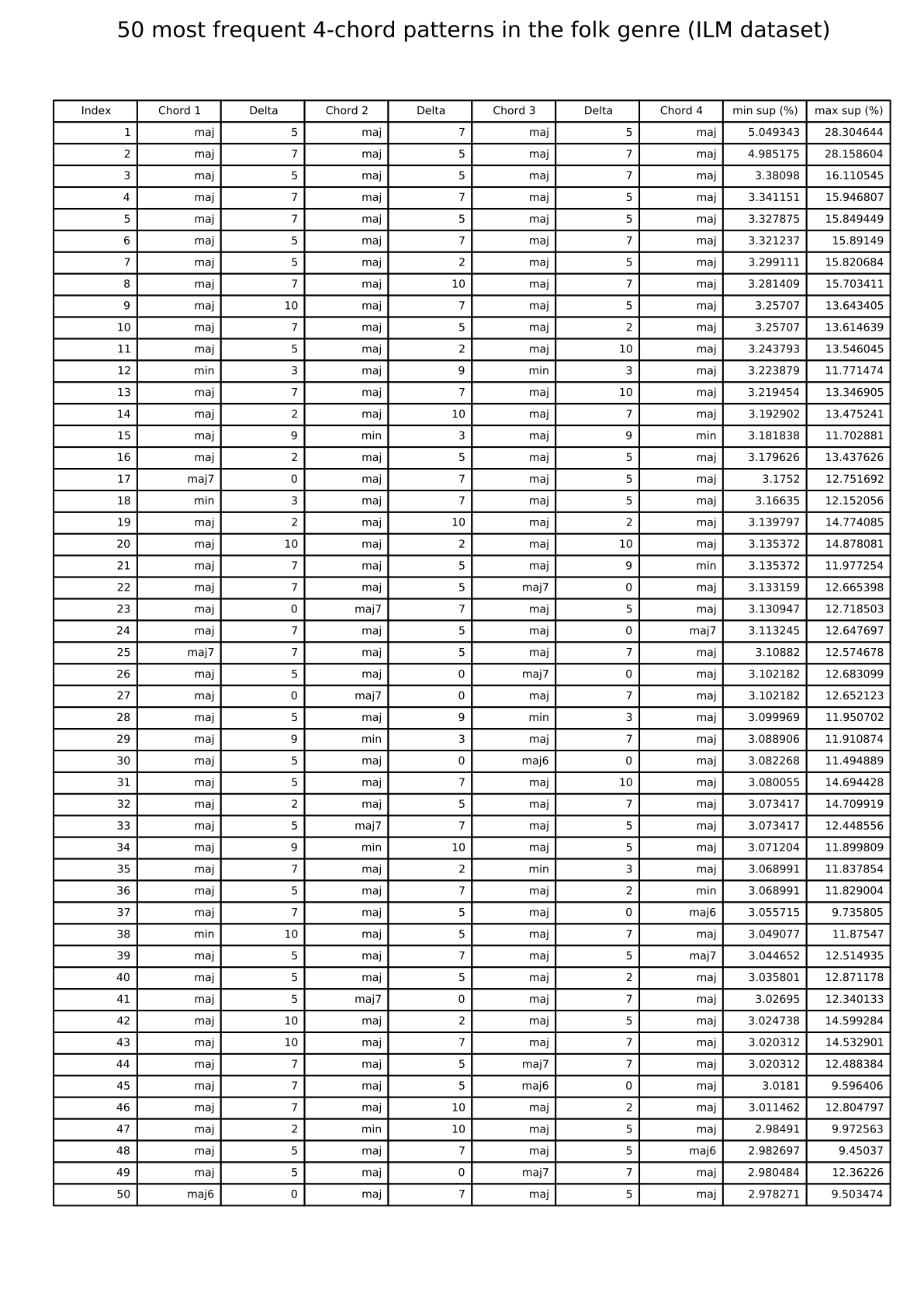{kind=link}
Jazz: 50 most frequent 4-chord patterns (ILM dataset)
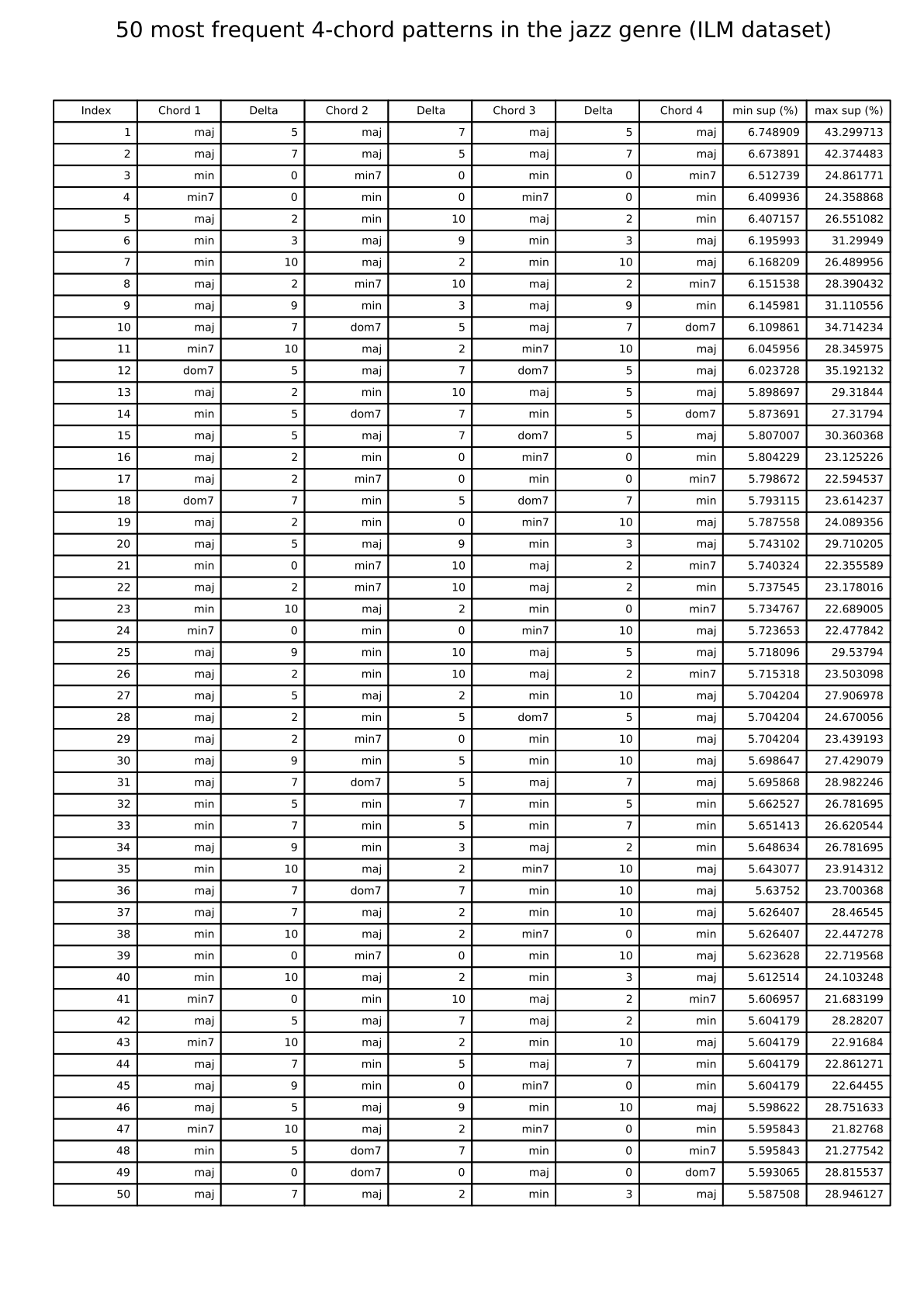{kind=link}
Reggae: 50 most frequent 4-chord patterns (ILM dataset)
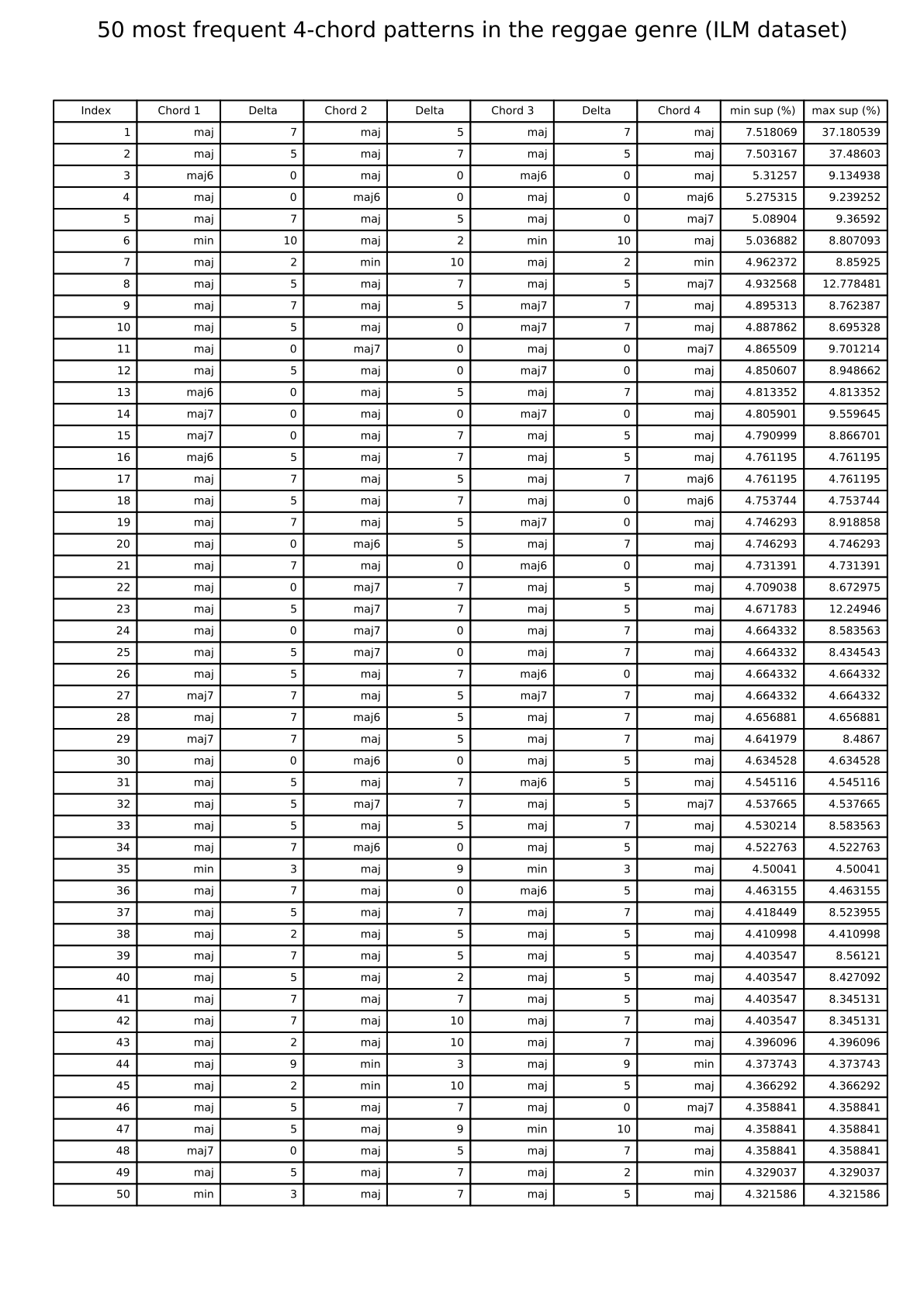{kind=link}
Rock'n'roll: 50 most frequent 4-chord patterns (ILM dataset)
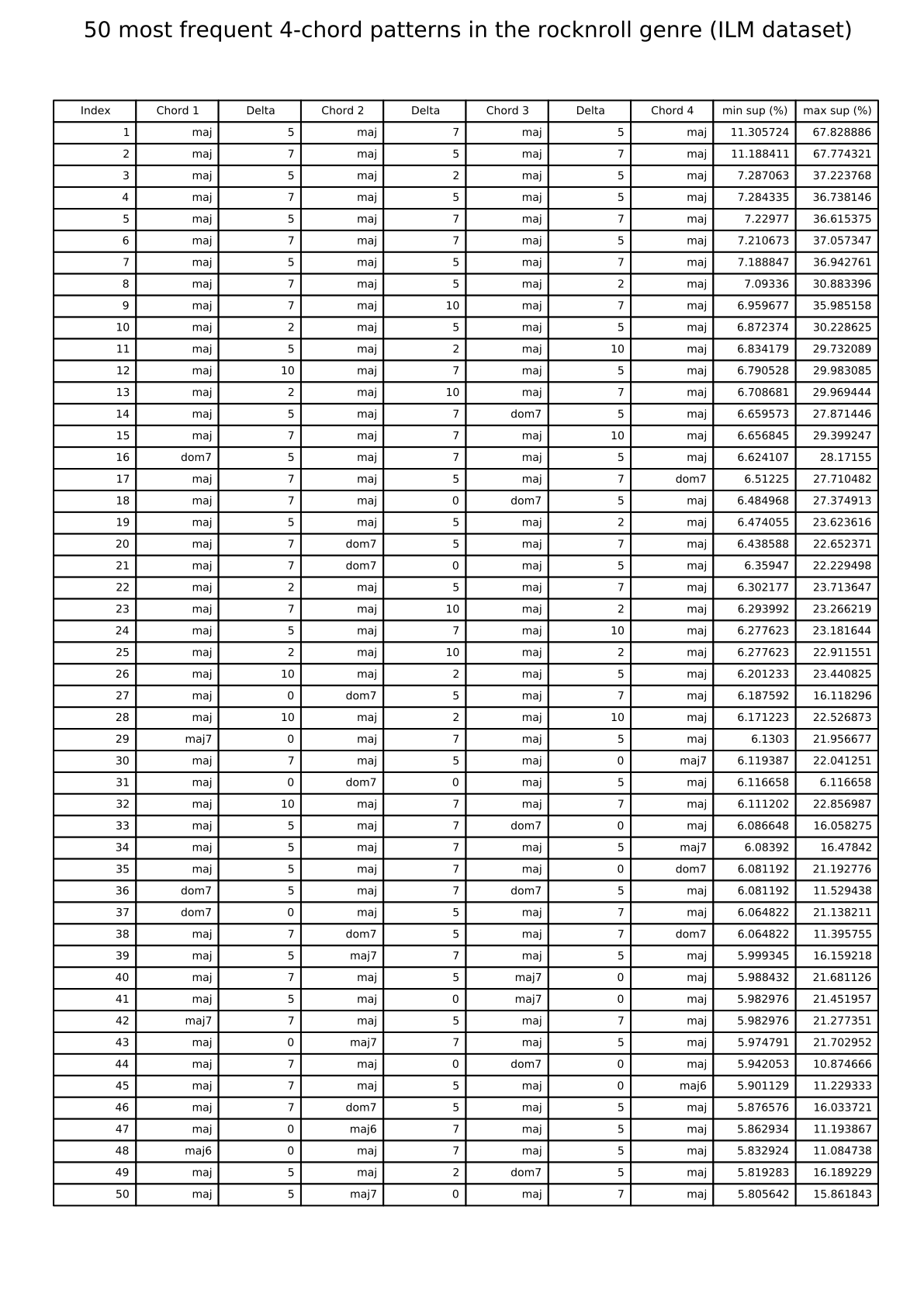{kind=link}
Frequent chord pattern directed graphs
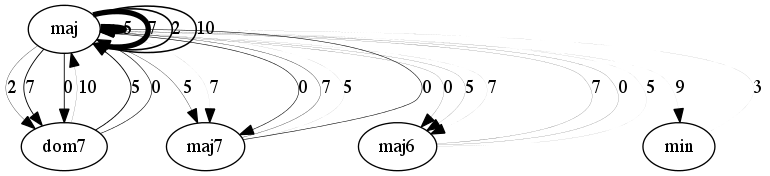
The figures below are graph-based representations of the 100 most frequent 4-chord progression patterns in pieces from the I Like Music commercial music collection, belonging to six different genres. The nodes represent the chord classes predicted from audio (Chordino Vamp plugin). The oriented edges describe the transitions between two chords. The thickness of the edges is proportional to the pattern support. The interval between chord roots is expressed in number of semitones above the chord root of the first chord and reported next to the edges (e.g. 5 semitones corresponds to a fourth, 7 semitones to a fifth, etc.).
Blues
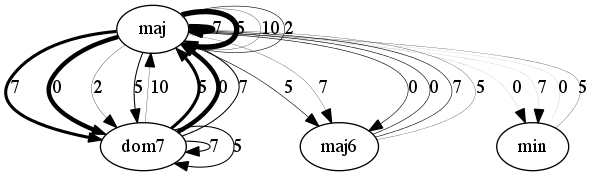
Classical
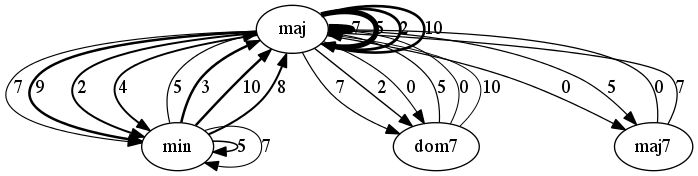
Folk
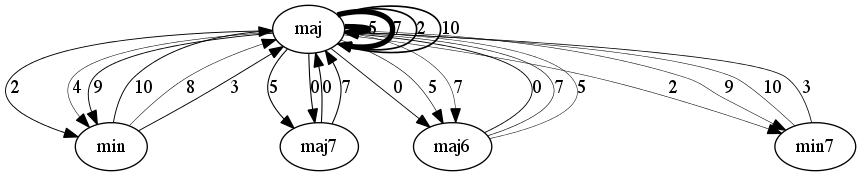
Jazz
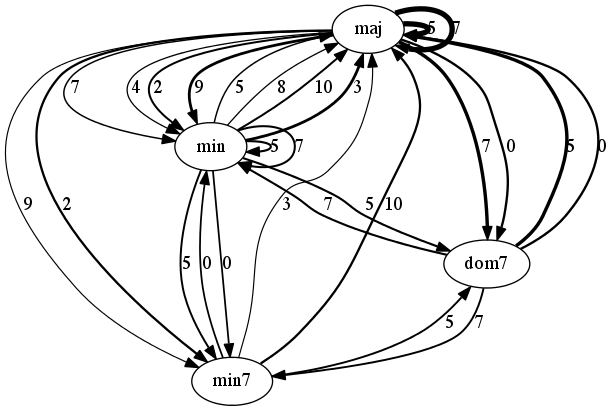
Reggae
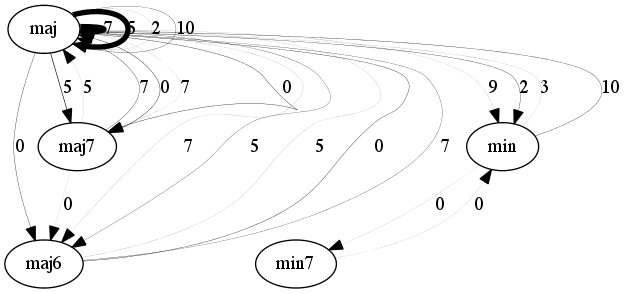
Rock'n'roll
Reference
M. Barthet and M. D. Plumbley and A. Kachkaev and J. Dykes and D. Wolff and T. Weyde, Big Chord Data Extraction and Mining, In Proc. International Conference on Interdisciplinary Musicology (CIM), 2014
A. Kachkaev and D. Wolff and M. Barthet and M. D. Plumbley and J. Dykes and T. Weyde, Visualising Chord Progressions in Music Collections: A Big Data Approach, In Proc. International Conference on Interdisciplinary Musicology (CIM), 2014
Contact
Correspondence can be addressed to: m.barthet@qmul.ac.uk
Acknowledgements
This project has been partly funded by the AHRC project Digital Music Lab - Analysing Big Music Data (grant AH\/L01016X\/1).